The other day, I was talking to a fellow ExtendSim model
developer, Aaron Kim from JWA Consulting. Aaron, who is a Lean consultant in
the health care industry, uses ExtendSim as part of his Lean toolbox.
Aaron described one of his recent simulation models, and it got
me thinking not only about how underutilized simulation is. Why are there not
more models built that simply compare concepts at a high level?
Many of you who have built models know how easy it is to A) include
too much detail or B) include processes around the fringe of the problem. Doing
either requires extra effort to model and can cause delays to an entire
project. I already suspected these were two root causes of unsuccessful
projects, but could they also be the two main reasons simulation is not used as
much as it should be?
When Aaron described his model, I thought it was a perfect
example of how valuable a simple simulation model can be. Aaron built a model
that compared two scheduling strategies. He stayed out of the weeds, so to
speak, and simply looked at the concepts involved.
Aaron was working with a clinic. The clinic classified their
patient visits into two basic categories – Short visits and Long visits. A Short
visit would take about 20 minutes, while a Long visit would take about 40
minutes. Generally, the Long visits were new patients and accounted for roughly
25 percent of all visits.
The clinic had been scheduling patients according to what
they called a “template” schedule. The
template schedule method works by setting up a template of appointment times
for both patient visit types. When a patient requests a specific time, the
clinic gives him or her the closest appointment block designated for that type
of visit.

For example, if a Long patient called in and requested an 8:10 a.m.
appointment, that slot could be open for a Short visit but not for a Long one.
In such cases, the clinic would then give the patient the closest appointment
time slotted for a Long patient, which might be an hour or two later. The
clinic felt that their open appointment scheduling was better, since it gave
patients appointments closer to their desired times.
An executive at the clinic suggested to Aaron that they
switch to a “Open” schedule because they thought it seemed more
patient-centric.
The open schedule method works by giving patients the
available time closest to their desired appointment time. For example, if a
patient wants a 9:00 a.m. appointment, and that slot is open, then the clinic
gives it to the patient, even if it causes gaps in the schedule.
Aaron felt like the open scheduling method would leave gaps
that were too small to see other patients and therefore result in the clinic
scheduling fewer patients overall. Because of that, Aaron felt the template
method would provide better patient satisfaction, as calculated by averaging
the difference between the desired appointment times and the given appointment
times.
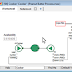
Aaron decided to build a simple model to compare the two scheduling
methods. He didn’t want an elaborate model with all the grueling details but rather
something simple, just to compare the two methods, to see which one would give
the better performance.
Rather than modeling all the doctors in the clinic, Aaron
chose to model just the scheduling of a single room with a single provider. He
also did not model how each doctor worked different hours during the week nor
how each took his or her lunch break at different times of the day nor how some
preferred to come in late on Mondays or golf on Wednesday afternoons or take
Friday afternoons off. Those were important details, but Aaron was not trying
to model the entire clinic; rather, he simply wanted to see the difference between
the two scheduling strategies.
Aaron’s model had a specified number of patients per day wanting
to book appointments for times over the following two weeks. Each patient would
be booked on both an open schedule and a template schedule. The key performance
measure of the system was the average time difference between the desired
appointment times and the given appointment times. The results are shown below.
The Patients Per Day was a variable that varied from 16 patients per
day to 20. The results showed that the more patients scheduled per day, the
better the template schedule outperformed the open schedule.

Because Aaron was just trying to compare two scheduling
policies, this turned out to be a quick modeling project. It took less than eight
hours to build the model and analyze the results.
The time spent building simple models like this one can pay
off immensely. But I hear far too many stories in which models take months to
get data and build and far too few in which models are built quickly just to
answer simple questions like this one. The challenge for us all is to know the
correct level of detail needed to answer the primary question. So the next time
you have a problem that a simulation model could be used to answer, don’t be
afraid to build the model, but please pay attention to the level of detail required.
It will take far less time to build if you can leave out the unnecessary
details, and it could make simulation a much more useful tool for you.